Turn Legislation into BeautifulSoup
So let’s say you want to dig up information on a city ordinance or track some other piece of legislation introduced by your City Council. How would you go about doing this? If your city happens to have some web developers handy, you might find your answer on a site like this:http://legistar.council.nyc.gov/
Great! Now you can search to your heart’s content.
But let’s say you want to dig deeper. You want to take every single record that the New York City Council has ever filed, plug each record into a spreadsheet (or statistical program of choice), and analyze that data to uncover meaningful trends. That’s 30,999 records on 310 separate web pages. How on earth are you going to pull that data?
Fortunately for you, there’s an export to Excel button to the rescue!
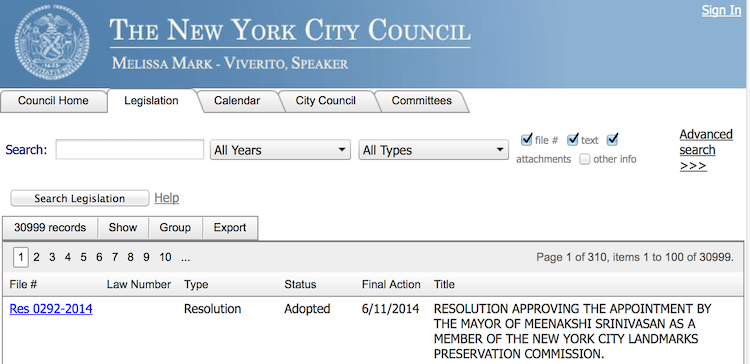
But wait, you can’t seem to open the exported .xls file in MS Excel. What gives? Turns out, the export button was a big fat liar - the file is in html format!
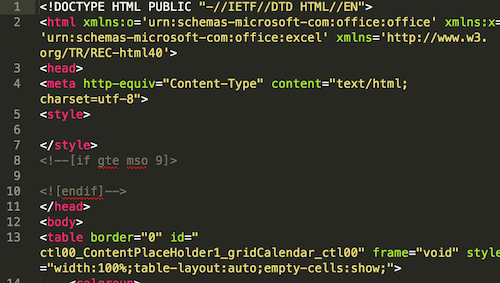
Alright, so how do we parse through all this gobbledygook (thanks, spellchecker) and get those damn legislation records? This is where our hero enters the fray - BeautifulSoup.
BeautifulSoup is a Python library that allows you to easily sift through the html by tag and extract the data you want. As BeautifulSoup’s authors so eloquently put on their website, the ease at which you can do this almost makes it seem as if you are scraping the data off of your screen.Here’s the Python script that I ran to parse through the html from the Legistar website, to extract all the records of City Council meetings, and to package that data into a much more manageable comma-delimited file:
from bs4 import BeautifulSoup
import csv
# Create .csv file with headers
f=csv.writer(open("nyccMeetings.csv","w"))
f.writerow(["Name", "Date", "Time", "Location", "Topic"])
# Use python html parser to avoid truncation
htmlContent = open("nyccMeetings.html")
soup = BeautifulSoup(htmlContent,"html.parser")
# Find each row
rows = soup.find_all('tr')
for tr in rows:
cols = tr.find_all('td') # Find each column
try:
names = cols[0].get_text().encode('utf-8')
date = cols[1].get_text().encode('utf-8')
time = cols[2].get_text().encode('utf-8')
location = cols[3].get_text().encode('utf-8')
topic = cols[4].get_text().encode('utf-8')
except:
continue
# Write to .csv file
f.writerow([names, date, time, location, topic])I think it would be useful to note some of the troubles I ran into while writing this script:
Specify your parser. It is very important to specify the type of html parser that BeautifulSoup will use to parse through the html tree form. The html file that I read into Python was not formatted correctly so BeautifulSoup truncated the html and I was only able to access about a quarter of the records. By telling BeautifulSoup to explicitly use the built-in Python html parser, I was able to avoid this issue and retrieve all records.
Encode to UTF-8. get_text() had some issues with encoding the text inside the html tags. As such, I was unable to write data to the comma-delimited file. By explicitly telling the program to encode to UTF-8, we avoid this issue altogether.Excellent! With all the legislative records written into a comma-delimited file, let the data analysis begin!